


Introduction
Durant les projets d’intégration Salesforce, le sujet du choix d’outil est souvent l’un des plus complexes.
Pour un besoin donné, que faut-il choisir ? Flows, Code, AppExchange ?
Cela fait maintenant des années que Salesforce améliore ses outils low-code avec notamment un grand investissement sur les flows.
Si on écoute à la lettre les recommandations Salesforce, il faut toujours choisir en priorité les flows.
Mais dans la pratique, est-ce toujours aussi simple ?
Dans cet article, je vais m’aider de mes 10 années d’expérience à développer des flows et de l’Apex pour répondre à la question suivante :
Quand vaut-il mieux utiliser du code plutôt que des flows ?
Pour répondre à cette question, je vais me focaliser sur la technologie dont j’ai eu le plus besoin tout au long de ma carrière, à savoir les triggered flows.
Triggered flows versus Apex Triggers
Depuis que j’ai commencé à travailler sur Salesforce, les triggered flows ont énormément changé. Salesforce a amélioré cette technologie au fil des années. Et il est vrai qu’aujourd’hui, pour un besoin de complexité simple ou moyenne, il n’existe je pense plus aucune limitation technique concernant les flows. Je détaillerai plus en détail en suivant ce que je considère être de complexité élevée.
En revanche, mon point de vue est que même si un flow est capable de réaliser la même chose que de l’Apex, est-il vraiment toujours plus avantageux de créer un flow plutôt qu’un trigger? Pour répondre à cette question, je vais commencer par parler d’un sujet qui me tient à coeur.
Maintenabilité
La maintenabilité est l’argument principal de Salesforce pour justifier l’utilisation des flows.
Effectivement, il est beaucoup plus facile pour un public non averti ou un administrateur Salesforce de s’initier au développement de flows. Il y a donc plus de personnes capables d’administrer un flow que d’écrire du code.
En revanche, est-ce que la maintenabilité d’un développement doit se baser entièrement sur les personnes en capacité de le corriger ou améliorer ? Je ne pense pas.
Pour justifier mon point de vue, je vais m’appuyer sur l’image suivante.
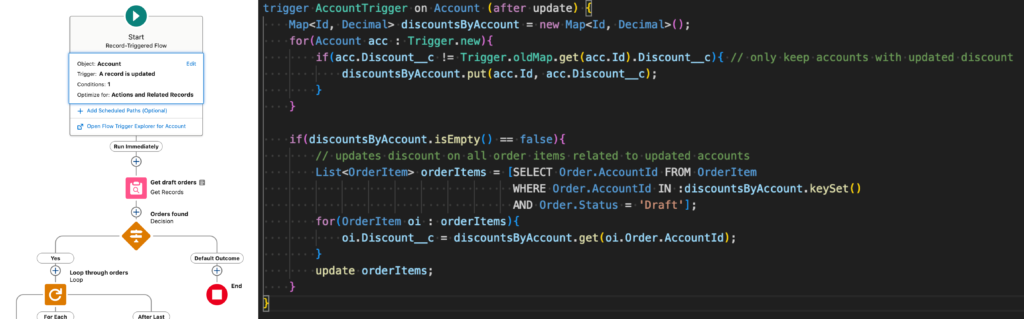
Ah mince excusez-moi, même avec un flow d’une simplicité extrême, il est impossible de voir l’ensemble du flow dès l’ouverture de celui-ci. J’ai oublié de dézoomer. On reprend.
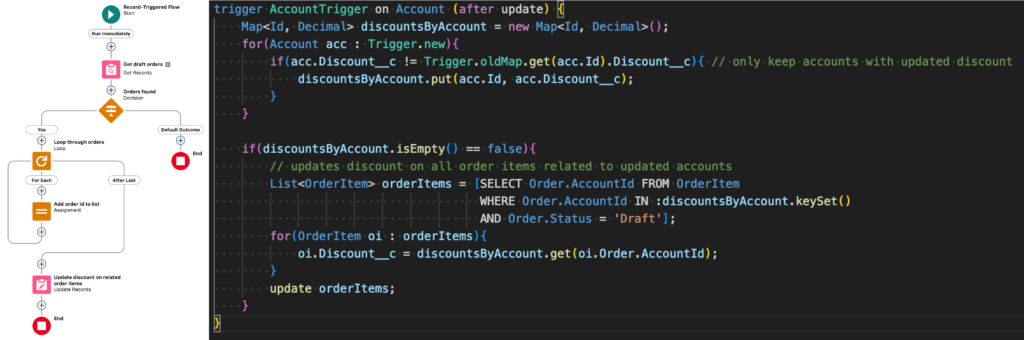
L’image ci-dessus représente un flow et un trigger juxtaposés. Ces deux composants qui rentrent dans la catégorie « simple » mentionnée précédemment ont exactement le même comportement : lorsque la valeur d’un champ personnalisé Discount__c de l’Account est mise à jour, elle doit être transmise à tous les order items liés aux orders au statut « Draft » de l’account en question.
En tant que développeurs, nous pouvons faire les remarques suivantes par rapport au flow et au trigger :
- Comme nous l’avons vu par le biais des captures d’écran, même un flow simple ne peut pas être visualiser entièrement sans l’intervention d’un clic
- Nous n’avons aucune visibilité sur les critères d’entrée du flow sans avoir cliqué sur l’élément de démarrage du flow
- Même si tout est correctement nommé et décrit dans un flow (ce qui n’arrive pas toujours malheureusement), il est impossible de voir ce qui se passe réellement sans avoir cliqué sur chaque composant du flow un par un. Il n’existe aucune recherche dans les flows permettant de vérifier rapidement où un champ peut-être mis à jour ou requêté. Contrairement au code.
- Le trigger lui est capable de requêter des enregistrements directement en se basant sur le parent. Dans le flow, nous sommes obligés de passer par deux éléments de requête et une boucle.
- En ouvrant le trigger, ou le trigger handler si vous appliquez à la lettre les bonnes pratiques (ce qui n’est pas le sujet de cet article), vous avez une visibilité totale sur votre écran de ce qui est automatisé
Comme vous l’aurez compris, même pour un flow simple, mon opinion est la suivante :
À partir du moment ou l’intégrateur Salesforce possède de bonnes connaissances en développement, il est toujours plus simple pour cette personne de maintenir du code plutôt qu’un flow.
Sauf que, ce n’est malheureusement pas si simple. Pour la maintenance d’une plateforme Salesforce, un autre facteur entre en compte : la personne qui intègre une fonctionnalité ne sera pas toujours celle qui maintiendra la plateforme. Imaginons que la prochaine personne n’a pas d’aussi bonnes compétences en code ou même aucune compétence dans ce domaine, dans ce cas-là, la maintenabilité de l’automatisation est catastrophique.
Et c’est là que l’argument de Salesforce de privilégier les flows commence à prendre du sens.
Mais contrairement à Salesforce qui ne s’appuie que sur ce dernier facteur, de notre côté, nous sommes à deux facteurs à prendre en compte :
- Souplesse : si nous écrivons du code, il doit pouvoir être maintenu dans le futur
- Complexité : le code peut s’avérer plus facile à maintenir pour les personnes compétentes en la matière
Concernant la complexité, nous avons déjà vu que même pour des flows simples, le code peut s’avérer plus facile à maintenir. Qu’en est-il des autres types de flows?
Complexité
Selon moi, la complexité d’une automatisation est engendrée par de multiples facteurs :
- le nombre d’opérations : nous avons déjà vu un flow et un trigger très simples comportant un très faible nombre d’opérations mais j’imagine que vous avez déjà ouvert des flows qui vous ont fait peur. C’était probablement dû au très grand nombre d’opérations qu’il contenait (requêtes, mises à jour de la base de données, décisions, …).
- la volumétrie de données traitée : ce facteur est probablement le plus compliqué à juger car il est important d’anticiper. Nous détaillerons plus en profondeur dans la suite de l’article.
- la synchronisation avec des systèmes externes : même si les flows ont bien évolué dans ce sens, les appels APIs semblent rester un sujet trop critique pour être traité hors du code. Que ce soit pour la gestion des erreurs, le système de logs, le débuggage et ou les tests unitaires.
- l’implication de traitements asynchrones : même si sur le papier les flows sont capables de traiter de l’asynchrone, leur capacité est très limitée. Surtout si l’automatisation nécessite de multiples traitements couplés par exemple à des appels APIs. Nous pouvons citer les mêmes exemples de limitations que pour la synchronisation avec les systèmes externes.
Focus sur la volumétrie de données
Si vous discutez avec un intégrateur Salesforce expérimenté et que vous lui demandez ce qu’il déteste le plus, il y a de grandes chances qu’il cite les governor limits.
Je serais le premier à le répondre même si je suis convaincu qu’elles sont le gardien d’une bonne qualité d’implémentation Salesforce.
Pour moi, c’est le plus gros soucis des flows. Ils sont supposés être optimisés pour limiter l’utilisation des appels DML (insert, update, …) ou des requêtes en bases de données mais nous n’avons aucun contrôle sur ce qui se passe réellement.
Tout au long de ma carrière, je ne compte plus le nombre d’interventions que j’ai dû réaliser pour migrer des flows vers du code.
Lors des intégrations, les flows avaient été privilégiés mais la volumétrie de données avait augmenté au fil du temps et les flows n’étaient plus capables de gérer les traitements. Ainsi, pour la plupart, les limites suivantes étaient souvent atteintes :
- nombre maximum de requêtes exécutées dans un même traitement
- nombre maximum d’appels DML exécutés dans un même traitement
- nombre maximum d’itérations dépassée
- Apex CPU time limit exceeded : temps de traitement trop long
Toutes ces expériences de migration me confortent dans l’idée suivante : ce n’est pas parce qu’un flow marche aujourd’hui qu’il marchera dans les prochains mois. Et je pense que c’est ce qu’il faut garder en tête en permanence avant de choisir d’intégrer des flows.
Alors dans ce cas-là, comment fait-on?
Avant de choisir entre créer un flow ou du code, voici les étapes de vérification que j’effectue :
- Quelle est la volumétrie de données actuelle qui va entrer dans l’automatisation ? Combien d’enregistrements répondant aux critères vont entrer dans l’exécution au même moment ?
- Quel est le ratio d’enregistrements répondant aux critères par rapport au nombre d’enregistrements total ?
- Quelle est la tendance de croissance du nombre d’enregistrements sur les derniers mois ? Pour cela je m’appuie sur la date de création des enregistrements groupée par mois, ce qui me permet de calculer une tendance.
- Le ratio calculé dans le point 2, combiné à la croissance calculée dans le point 3, permet de répondre à la question suivante : dans quelques mois, combien d’enregistrement vont être potentiellement traités en même temps dans l’exécution de l’automatisation ?
- Enfin, la question la plus importante : est-ce que l’automatisation va déclencher l’exécution d’autres automatisations déjà intégrées ? Est-ce que l’automatisation va par exemple mettre à jour des comptes et un flow déjà existant sur les comptes va être exécuté ?
Pour rentrer dans le concret, nous allons imaginer un exemple :
Lorsqu’une ligne de commande est insérée dans la plateforme Salesforce, je souhaite identifier le compte lié à la commande pour mettre à jour ses statistiques d’achat (montant total de ses achats par famille de produit) et aussi mettre à jour les statistiques d’achat du produit concerné.
Reprenons la liste des questions que nous devons nous poser :
- Les lignes de commandes sont intégrées à Salesforce par le biais d’un système externe. Aujourd’hui, le système externe envoie environ 100 lignes de commande en même temps.
- Je n’ai pas de critère d’entrée, l’automatisation doit s’exécuter pour chaque ligne de commande insérée. Nous devons donc traiter les 100 lignes de commandes.
- Analysons maintenant la croissance de mon entreprise en termes de commandes et lignes de commandes. Voici la tendance de croissance sur les 8 derniers mois :

La croissance moyenne est donc d’environ 9 lignes de commandes par mois.
- Dans 11 mois, nous devrions donc atteindre les 200 lignes de commandes envoyées à Salesforce dans la même transaction.
- Il existe déjà deux autres automatisations sous la forme de deux flows, l’un lié à la mise à jour du compte et l’autre à celle du produit. Le premier analyse les statistiques d’achat du compte pour mettre à jour un scoring personnalisé déjà présent sur le compte. Le deuxième sur le produit permet de désactiver le produit lorsqu’il n’y a plus de stock. D’autres flows existent pour mettre à jour opportunités et devis en fonction du scoring du compte et de la désactivation du produit.
Étant donné que dans les prochains mois 200 lignes de commandes seront insérées dans la même exécution, imaginons le pire scénario :
- Ces 200 lignes de commandes concernent 200 commandes différentes mais aussi 200 comptes différents
- Ces 200 lignes de commandes concernent 200 produits différents
Avec tous ces paramètres pris en compte, nous pouvons déjà facilement anticiper tous les problèmes que nous pourrons rencontrer en implémentant ce besoin sous forme de flow :
- Ce flow nécessitera beaucoup de boucles pour permettre de calculer les statistiques par compte et par produit, contrairement à du code qui lui pourra utiliser des Map et des requêtes groupées. Il est possible que nous atteignons donc la limite de 2000 itérations.
- Ce flow entraînera l’enchaînement de nombreux traitements dans une même transaction, donc beaucoup de requêtes et d’appels DML
Inévitablement, si nous implémentons ce besoin sous la forme d’un flow, il finira par ne plus fonctionner d’ici quelques mois. C’est donc un cas parfait où l’utilisation d’un trigger est préférable à celle d’un flow, même si le flow est capable à l’instant t de répondre au besoin.
Tant que nous sommes sur le sujet des performances de flow, nous pouvons lister ici les raisons pour lesquelles, selon moi, les flows ne pourront jamais être aussi performants que du code :
- requêtage des champs d’un parent : action pourtant très basique dans du code et très utilisée, il est toujours impossible de requêter les champs d’un parent lorsque l’on effectue un « Get records » dans un flow.
- absence de Map : probablement le type de collection le plus utilisé lorsque l’on écrit du code Salesforce pour justement éviter de parcourir de multiples boucles inutiles. Rien de prévu pour le moment sur l’utilisation de map dans des flows tel que le montre cette idée, pourtant très populaire dans la communauté.
- requêtes groupées : requêtes très utiles notamment pour effectuer des calculs et éviter d’avoir à parcourir tous les enregistrements un par un
Conclusion
Si nous devions extraire les points les plus importants, voici ce que je pense qu’il faut retenir :
- Non les flows ne sont pas toujours la solution prioritaire à envisager lorsque l’on souhaite automatiser un process dans Salesforce.
- Lorsque l’équipe actuelle ou future possède des compétences dans le code, il est souvent plus facile de maintenir du code que des flows.
- Les process complexes faisant intervenir de l’asynchrone ou des appels à des systèmes externes (API) devraient être intégrés par du code.
- Lorsqu’un besoin est étudié et que le choix doit être fait entre implémentation avec du code ou des flows, il faut anticiper la volumétrie de données future car les flows ne sont pas capables de gérer une volumétrie importante.
- Les flows sont moins performants que le code. Les process complexes peuvent engendrer des atteintes de limites alors que le code saura mieux les gérer.
